- 135 Posts
- 118 Comments


 1·13 days ago
1·13 days agoNeither does Git though.
Doesn’t it, though? I mean, you can update a submodule’s history directly from the consumer package. That’s the whole point of submodules. Otherwise you would be better off by just wget something into your project.


 11·1 month ago
11·1 month agoThat’s perfectly fine. It’s a standardization process. Its goal is to set in stone a specification that everyone agrees to. Everything needs to line up.
In the meantime, some compiler vendors provide their own contracts support. If you feel this is a mandatory feature, nothing prevents you from using vendor-specific implementations. For example, GCC has support for contracts since at least 2022, and it’s mostly in line with the stuff discussed in the standardization meetings.
Still no contracts?
In line with the release process for C++ standard specifications, where standards ship every 3 years but alternate between accepting new features and feature freeze releases, C++23 was the last release that was open to new features. This would mean C++26 is a feature freeze release following the new features introduced in C++23.

named arguments
Is this supposed to be a critical feature?
I don’t see why using submodules as a package manager should excuse their endless bugs.
I don’t know what are these “endless bugs” you’re talking about. Submodules might have a UX that’s rough on the edges, but there are really no moving parts in them as they basically amount to cloning a repo and checking out a specific commit.
Do you actually have any specific, tangible issue with submodules? Even in the cases you’re clearly and grossly misusing them

Aside from the obvious UX disaster, Git has some big issues:
I find this blend of claims amusing. I’ve been using Git for years on end, with Git LFS and rebase-heavy user flows, and for some odd reason I never managed to stumble upon these so-called “disasters”. Odd.
What I do stumble upon are mild annoyances, such as having to deal with conflicts when reordering commits, or the occasional submodule hiccup because it was misused as a replacement for a package manager when it really shouldn’t, but I would not call any of these “disasters”. The only gripe I have with Git is the lack of a command to split a past commit into two consecutive commits (a reverse of a squash commit), specially when I accidentally bundled changes to multiple files that shouldn’t have been bundled. It’s nothing an interactive rebase doesn’t solve, but it’s multiple steps that could be one.
Can you point out what is the most disastrous disaster you can possibly conceive about Git? Just to have a clear idea where that hyperbole lies.

ccache folder size started becoming huge. And it just didn’t speed up the project builds, I don’t remember the details of why.
That’s highly unusual, and suggests you misconfigured your project to actually not cache your builds, and instead it just gathered precompiled binaries that it could not reuse due to being misconfigured.
When I tried it I was working on a 100+ devs C++ project, 3/4M LOC, about as big as they come.
That’s not necessarily a problem. I worked on C++ projects which were the similar size and ccache just worked. It has more to do with how you’re project is set, and misconfigurations.
Compilation of everything from scratch was an hour at the end.
That fits my usecase as well. End-to-end builds took slightly longer than 1h, but after onboarding ccache the same end-to-end builds would take less than 2 minutes. Incremental builds were virtually instant.
Switching to lld was a huge win, as well as going from 12 to compilation 24 threads.
That’s perfectly fine. Ccache acts before linking, and naturally being able to run more parallel tasks can indeed help, regardless of ccache being in place.
Surprisingly, ccache works even better in this scenario. With ccache, the bottleneck of any build task switches from the CPU/Memory to IO. This had the nice trait that it was now possible to overcommit the number of jobs as the processor was no longer being maxed out. In my case it was possible to run around 40% more build jobs than physical threads to get a CPU utilization rate above 80%.
I was a linux dev there, the pch’s worked, (…)
I dare say ccache was not caching what it could due to precompiled headers. If you really want those, you need to configure ccache to tolerate them. Nevertheless it’s a tad pointless to have pch in a project for performance reasons when you can have a proper compiler cache.
std::unordered_map is one of the worst ones
It should be noted that the benchmark focused on the
std::unordered_mapimplementation from GCC 13.2.0. I’m not sure if/how this conclusion can be extended to other implementations such as msvc or clang.
What is the advantage of rebasing?
You get a cleaner history that removes noise from the run-of-the-mill commit auditing process. When you audit the history of a repo and you look into a feature branch, you do not care if in the middle of the work a developer merged with x or y branch. What you care about is what changes were made into mainline.
Because this is a casual discussion and that’d be more effort than I’m willing to put in.
I didn’t asked you to write a research paper. You accused Git of suffering from usability issues and I asked you to provide concrete examples.
And apparently that’s an impossible task for you.
If you cannot come up with a single example and instead write a wall of text on you cannot put the effort to even provide a single opinion… What does this say about your claims?
I think nobody talks about it because it doesn’t show history
What do you mean it doesn’t show history? It’s perhaps the only thing it handles better than most third-party git GUIs.
It’s not and no one cares about numbers anymore.
The only people who ever cared about svn’s numbering scheme were those who abused it as a proxy to release/build versions, which was blaming the tools for the problems they created for themselves.
deleted by creator
I initially found git a bit confusing because I was familiar with mercurial first, where a “branch” is basically an attribute of a commit and every commit exists on exactly one branch.
To be fair, Mercurial has some poor design choices which leads to a very different mental model of how things are expected to operate in Git. For starters, basic features such as stashing local changes were an afterthought that you had to install a plugin to serve as a stopgap solution.
think the lack of UI
Even git ships with git-ui. It’s not great, but just goes to show how well informed and valid your criticism is.
Sure if you never branch, which is a severely limited way of using git.
It’s quite possible to use Git without creating branches. Services like GitHub can automatically create feature branches for you as part of their ticket-management workflow. With those tools, you start to work on a ticket, you fetch the repo, and a fancy branch is already there for you to use.
You also don’t merge branches because that happens when you click on a button on a PR.
I think a common misconception is that there’s a “right way to do git” - for example: “we must use Gitflow, that’s the way to do it”.
I don’t think this is a valid take. Conventions or standardizations are adopted voluntarily by each team, and they are certainly not a trait of a tool. Complaining about gitflow as if it’s a trait of Git is like complaining that Java is hard because you need to use camelCase.
Also, there is nothing particularly complex or hard with gitflow. You branch out, and you merge.
Nonetheless
You didn’t provided a single concrete example of something you actually feel could be improved.
The most concrete complain you could come up was struggling with remembering commands, again without providing any concrete example or specific.
Why is it so hard for critics to actually point out a specific example of something they feel could be improved? It’s always “I’ve heard someone say that x”.
Git is ugly and functional.
I don’t even think it’s ugly. It just works and is intuitive if you bother to understand what you’re doing.
I think some vocal critics are just expressing frustration they don’t “get” a tool they never bothered to learn, particularly when it implements concepts they are completely unfamiliar with. At the first “why” they come across, they start to blame the tool.
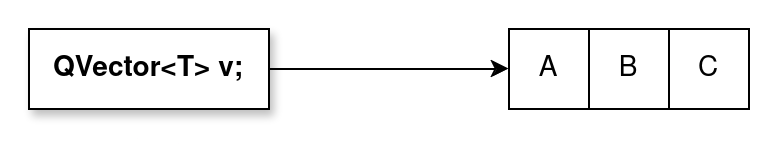
Not true. The whole point of monorepos is that you track everything in a single repo. There is absolutely no requirement or constraint to avoid using specific features of specific VCSs or even package managers.