- 3 Posts
- 99 Comments

 1·3 months ago
1·3 months agoYeah, I don’t really need to backup the system, except for a list of installed software, but I guess that’s all included somewhere in
~/.localor whatever, since it’s flatpak homebrew and steam.
Did anything specific break?
I’ll look into vorta, thanks!
On my NixOS and Arch machines I used ZFS snapshots for backups. That’s why I specifically asked for Aurora / Bazzite users.
Question for all Bazzite/Aurora users: what do you use to make backups of your machine?
I’m using Pikabackup to make backups of
/home, but I’m not sure if there’s a better way?
yum install -y mint-choc # 😋

I’ve had it at the 27th for a few years in my calendar now, but I have no idea why, lol.
Apparently the official birthday should be August 25th, so maybe I mixed those up?
That look delicious, tysm!
 15·5 months ago
15·5 months ago“Capitalism creates innovation!”
The innovation: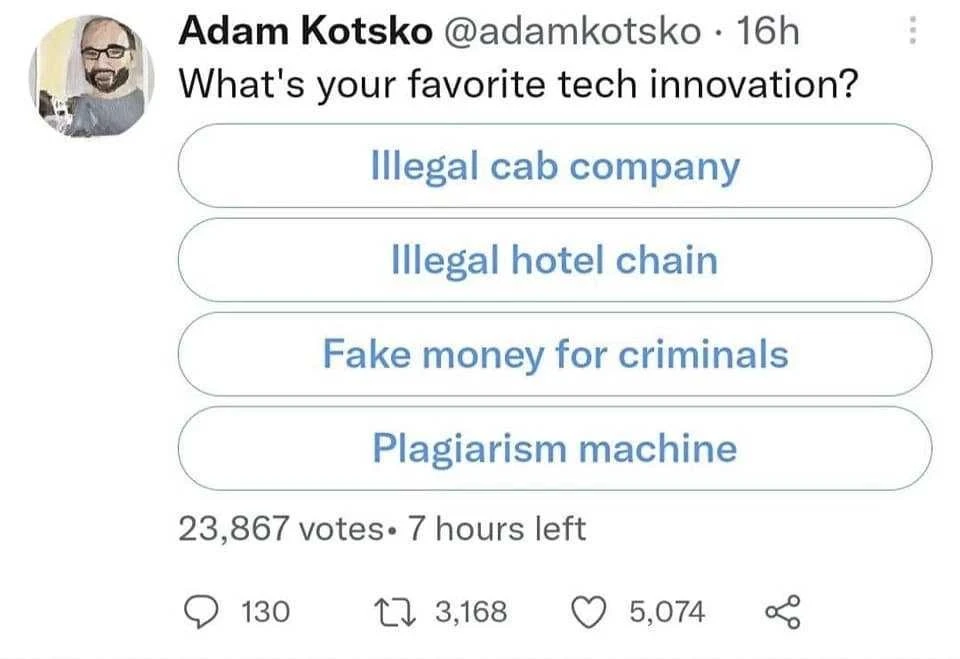
Well yes, assuming that:
- you trust the hardware manufacturer
- you can install your own keys (i.e. not locked by vendor)
- you secure your bios with a secure password
- you disable usb / network boot
With this you can make your laptop very tamper resistant. It will be basically impossible to tamper with the bootloader while the laptop is off. (e.g install keylogger to get disk-encryption password).
What they can do, is wipe the bios, which will remove your custom keys and will not boot your computer with secure boot enabled.
Something like a supply-side attack is still possible however. (e.g. tricking you into installing a malicious bootloader while the PC is booted)
Always use security in multiple layers, and to think about what you are securing yourself from.
And don’t just fork it on GitHub, if the original repo gets deleted, any forks might too.
Also do a
git clonelocally, or set up a mirror on another host.
 5·7 months ago
5·7 months agoRemember: militaries usually buy from the lowest bidder, so anything military-grade is probably low quality.
Also, email isn’t a great medium for communicating securely, since the other party has to be just as mindful about security as you; otherwise it’s basically security theater.
You could try [0-9] instead?
awk '/\/dev\/loop[0-9]/ {print}'If you have a larger sample of input and desired output, people can help you better.

I get it, sometimes you just do something for the challenge.
It’s really great what you can accomplish when you know a little more than the bare minimum of the tools at your disposal (^^,)
And I had the same experience after learning a bit more about awk for the fist time, hahaha.
Virtual memory is different from swap memory.
Swap memory is used when you run out of physical memory, so the memory is extended to your storage.
Virtual memory is an abstraction that lies between programs using memory and the physical memory in the device. It can be something like compression and memory-mapped files, like mentioned.
And yes, some swap is still useful, up to something like 4G for larger systems.
And if you want to hibernate to disk, you may need as much swap as your physical memory. But maybe that’s changed. I haven’t done that in years.
In the end I’ve used the first command you wrote, because KISS, but I appreciate your explanation
There’s no shame in combining multiple tools, that’s what pipelines are all about 😄.
Also there’s a different tool that I would use if I want to output a specific column:
awkdf -h —output=avail,source | awk ‘/\/dev\/dm-2/ {print $1}’For lines matching
/dev/dm-2print the first column.awksplits columns on whitespace by default.But I would probably use grep+awk.
Sed is definitely a very powerful tool, which leads to complex documentation. But I really like the filtering options before using the search/replace.
You can select specific lines, with regex or by using a line number; or you can select multiple lines by using a comma to specify a range.
E.g.
/mystring/,100s/input/output/g: in the lines starting from the first match of/mystring/until line100, replaceinputwithoutput
The easiest way is probably without sed, which you mentioned:
df -h --output=avail /dev/dm-2| tail -n1But purely with sed it would be something like this:
df -h --output=avail,source | sed -n ‘/\/dev\/dm-2/s!/dev/dm-2!!p’-ntells sed to not print lines by default/[regex]/selects the likes matching regex. We need to escape the slashes inside the regex.s///does search-and-replace, and has a special feature: it can use any character, not just a slash. So I used three exclamation points instead , so that I don’t need to escape the slashes. Here we replace the device with the empty string.pprints the resultCheck the sed man page for more details: https://linux.die.net/man/1/sed
 2·9 months ago
2·9 months ago🦀 🦀🦀🦀🦀🦀🦀🦀

{kind=link}
{kind=link}
I’ll check it out, thanks!